Crypto-API Released
September 7, 2010
Crypto-API (hackage, haddock) 0.0.0.1 is now on Hackage.
Crypto-API is a generic interface for cryptographic operations, platform independent quality Entropy, property tests and known-answer tests (KATs) for common algorithms, and a basic benchmark infrastructure. Maintainers of hash and cipher implementations are encouraged to add instances for the classes defined in Crypto.Classes. Crypto users are similarly encouraged to use the interfaces defined in the Classes module.
Previous blogs on crypto-api have discussed its design and the RNG interface. These were to aid design discussion, so note the code there won’t work without minor changes.
Example: Hashes
An example class instance:
instance Hash MD5Context MD5Digest where
outputLength = Tagged 128
blockLength = Tagged 512
initialCtx = md5InitialContext
updateCtx = md5Update
finalize = md5Finalize
The hash user can remain agnostic about which type of hash is used:
authMessage :: Hash ctx dgst => B.ByteString -> MacKey -> dgst -> Bool authMessage msg k = (==) (hmac' k msg) hashFile :: Hash c d => FilePath -> IO d hashFile = liftM hash L.readFile
Example: Block Cipher
Users of block cipher instances probably want to use Crypto.Modes:
import Crypto.Classes
import Crypto.Modes (cbc)
import Data.Serialize (encode)
cipherMsgAppendIV :: (BlockCipher k) => k -> B.ByteString -> IO B.ByteString,
cipherMsgAppendIV msg = do
iv <- getIVIO
return $ B.append (encode iv) (cbc k iv msg)
Example RNG
Its easy to get a DRBG (aka PRNG) that can be used for generating seed material for keys, building asymmetric keys, obtaining initialization vectors, nonces, or many other uses. See Crypto.Random (which users System.Crypto.Random for entropy):
newGenIO :: CryptoRandomGen g => IO g genBytes :: (CryptoRandomGen g) => g -> ByteLength -> Either GenError (ByteString, g) getIV :: (CryptoRandomGen g, BlockCipher k) => g -> Either GenError (IV k, g) buildKeyPair :: CryptoRandomGen g => g -> BitLength -> Maybe ((p, p), g)
Tests
A quick peek in the Test.Crypto module will show you that testing is decent (particularly for AES) and getting better all the time.
Given a BlockCipher instance the entire test code for an AES implementation is:
-- Omitting hack-job instances for SimpleAES in this snippet
main = do
ts <- makeAESTests (AESKey $ B.replicate 16 0)
runTests ts
This automatically reads in hundreds of NIST Known Answer Tests (KATs) and checks the implementation. A lesser infrastructure exists for testing Hashes. Cipher property tests are still needed.
Example: Benchmarking
As with tests, benchmarking is quite simple:
import Data.Digest.Pure.MD5 import Benchmark.Crypto import Criterion.Main main = defaultMain [benchmarkHash (undefined :: MD5Digest) "pureMD5"]
Closing
So please, if you maintain a hash, cipher, or other cryptographic primitive please add instances for the crypto-api classes. If you need these primitives then consider using the crypto-api interfaces, allowing you to remain algorithm and implementation agnostic in all your low level code.
A Better Foundation for Random Values in Haskell
September 2, 2010
RandomGen – The Old Solution
Mathematicians talk about random bits and many programmers talk about streams of random bytes (ex: /dev/urandom, block cipher counter RNGs), so its a bit odd that Haskell adopted the RandomGen class, which only generates random Ints. Several aspects of RandomGen that are non-ideal include:
- Only generates Ints (Ints need to be coerced to obtain other types)
- By virtue of packaging it is often paired with StdGen, a sub-par generator
- Mandates a ‘split’ operation, which is non-sense or unsafe for some generators (as BOS pointed out in a comment on my last post)
- Doesn’t allow for generator failure (too much output without a reseed) – this is important for cryptographically secure RNGs
- Doesn’t allow any method for additional entropy to be included upon request for new data (used at least in NIST SP 800-90 and there are obvious default implementations for all other generators)
Building Something Better
For these reasons I have been convinced that building the new crypto-api package on RandomGen would be a mistake. I’ve thus expanded the scope of crypto-api to include a decent RandomGenerator class. The proposal below is slightly more complex than the old RandomGen, but I consider it more honest (doesn’t hide error conditions / necessitate exceptions).
class RandomGenerator g where
-- |Instantiate a new random bit generator
newGen :: B.ByteString -> Either GenError g
-- |Length of input entropy necessary to instantiate or reseed a generator
genSeedLen :: Tagged g Int
-- |Obtain random data using a generator
genBytes :: g -> Int -> Either GenError (B.ByteString, g)
-- |'genBytesAI g i entropy' generates 'i' random bytes and use the
-- additional input 'entropy' in the generation of the requested data.
genBytesAI :: g -> Int -> B.ByteString -> Either GenError (B.ByteString, g)
genBytesAI g len entropy =
... default implementation ...
-- |reseed a random number generator
reseed :: g -> B.ByteString -> Either GenError g
Compared to the old RandomGen class we have:
- Random data comes in Bytestrings. RandomGen only gave Ints (what is that? 29 bits? 32 bits? 64? argh!), and depended on another class (Random) to build other values. We can still have a ‘Random’ class built for RandomGenerator – should we have that in this module?
- Constructing and reseeding generators is now part of the class.
- Splitting the PRNG is now a separate class (not shown)
- Generators can accept additional input (genBytesAI). Most generators probably won’t use this, so there is a reasonable default implementation (fmap (xor additionalInput) genBytes).
- The possibility to fail – this is not new! Even in the old RandomGen class the underlying PRNGs can fail (the PRNG has hit its period and needs a reseed to avoid repeating the sequence), but RandomGen gave no failure mechanism. I feel justified in forcing all PRNGs to use the same set of error messages because many errors are common to all generators (ex: ReseedRequred) and the action necessary to fix such errors is generalized too.
In Closing
The full Data.Crypto.Random module is online and I welcome comments, complaints and patches. This is the class I intend to force users of the Crypto API block cipher modes and Asymmetric Cipher instances to use, so it’s important to get right!
GHC on ARM
January 19, 2010
During my “Linux Kernel Modules with Haskell” tech talk I mentioned my next personal project (on my already over-full plate) would be to play with Haskell on ARM. I’m finally getting around to a little bit of playing! Step zero was to get hardware so I acquired a touchbook – feel free to ignore all the marketing on that site (though I am quite happy with it) and just understand it is the equivalent of a beagleboard with keyboard, touch-pad, touch screen, speakers, wifi, bluetooth, two batteries, more USB ports, and a custom Linux distribution.
Step 1: Get an Unregistered Build
To start its best to bypass the porting GHC instructions and steal someone elses porting effort in the form of a Debian package (actually, three debian packages). Convert them to a .tar.gz (unless you have a debian OS on your ARM system) using a handy deb2targz script. Now untar them onto your ARM system via “sudo tar xzf oneOfThePackages.tar.gz -C /” . Be sure to copy the package.conf as it seems to be missing from the .debs “sudo cp /usr/lib/ghc-6.10.4/package.conf.shipped /var/lib/ghc-6.10.4/package.conf”. After all this you should have a working copy of GHC 6.10.4 – confirm that assertion by compiling some simple test programs.
I now have my copy of 6.10.4 building GHC 6.12.1. The only hitch thus far was needing to add -mlong-calls to the C options when running ./configure. With luck I will soon have an unregistered GHC 6.12.1 on my ARM netbook. I’ll edit this post tomorrow with results (yes, I’m actually compiling on the ARM and not in an x86 + QEMU environment).
Step 2: Get a registered build – upstream patches
This is where things become more black-box to me. I want to make a native code generator (NCG) for GHC/ARM. There are some decent notes about the RTS at the end of the previously mentioned porting guide and there is also a (up-to-date?) page on the NCG. Hopefully this, combined with the GHC source, will be enough but I’ll probably be poking my head into #ghc more often.
Step 3: Write more Haskell
The purpose of all of this was to use Haskell on my ARM system. Hopefully I’ll find time to tackle some problems that non-developers will care about!
Lightweight USB Framework for AVRs (LUFA)
December 8, 2009
Lately I’ve been killing off course requirements by taking project based courses. Happily, Bart Massey offered a Linux device driver course that gave me an opportunity to get my hands dirty in the embedded world again. The project was to make an AVR based USB gadget do something… anything. Most prior experience with µCs was with Rabbits – a fitting name seeing as the useful and higher level libraries seemed to multiply like rabbits. Unfortunately, the AVRs didn’t have any apparent high level library for USB; many of the examples used commented byte arrays as USB descriptors. While understandable, this feels harder to debug, ugly, and just generally wrong. Enter LUFA.
LUFA
LUFA is a high-level USB library for AVRs generously released under MIT. It has considerable documentation, but no real guide stating what the bare-minimum functions are for any new/custom gadget – this is my attempt at providing such a guide. After you verify your AVR is supported by LUFA go ahead and download LUFA to an includes directory for your project. All code here is made possible by LUFA and its included examples – I’ll only claim to being the original author of any and all bugs.
My Device
Before going any further you should have an understanding of what your device will do, how many and what type of USB endpoints it will use (BULK, INTERRUPT, CONTROL, ISOCRONOUS), and what driver will support it. If you are making something that will use a generic driver, such as a HID, then you probably can stop here as there is plenty of code for you to use – this post is aimed at people making custom devices.
I’m using a Teensy 2.0 with three bulk interfaces (two OUT one IN). One OUT provides commands to the gadget, which will change its state. Another OUT will send jobs to the gadget and the final IN will read the results of those jobs. This requires a custom driver which I and several other folks developed for course work.
The Makefile
Its probably safe for you to rip-off one of the makefiles from an example in LUFA/Demo/Devices/LowLevel/. Noitice several of the defines change the API, defines I used for this post/project include:
-DUSB_DEVICE_ONLY # Saves space if you only need gadget-side code -DNO_STREAM_CALLBACKS # Changes the API to exclude any callbacks on streams -DINTERRUPT_CONTROL_ENDPOINT # So you don't have to call USB_USBTask() manually on a regular basis -DUSE_FLASH_DESCRIPTORS # Save RAM, leave these in the Flash -DUSE_STATIC_OPTIONS="(USB_DEVICE_OPT_FULLSPEED | USB_OPT_AUTO_PLL)"
EDIT: All the makefiles I’ve seen are broken, they don’t properly track dependencies, so either fix that or be sure to ‘make clean’ prior to each build.
Enumeration
When your gadget is plugged in its going to have to enumerate its interfaces by sending descriptors to the host. Start by declaring a global USB_Descriptor_Device_t along with Language, Manufacturer and Product structures:
USB_Descriptor_Device_t PROGMEM DeviceDescriptor =
{
.Header = {.Size = sizeof(USB_Descriptor_Device_t), .Type = DTYPE_Device},
.USBSpecification = VERSION_BCD(01.10),
.Class = 0xff,
.SubClass = 0xaa,
.Protocol = 0x00,
.Endpoint0Size = FIXED_CONTROL_ENDPOINT_SIZE,
.VendorID = 0x16c0,
.ProductID = 0x0478,
.ReleaseNumber = 0x0000,
.ManufacturerStrIndex = 0x01,
.ProductStrIndex = 0x02,
.SerialNumStrIndex = USE_INTERNAL_SERIAL,
.NumberOfConfigurations = FIXED_NUM_CONFIGURATIONS
};
USB_Descriptor_String_t PROGMEM LanguageString =
{
.Header = {.Size = USB_STRING_LEN(1), .Type = DTYPE_String},
.UnicodeString = {LANGUAGE_ID_ENG}
};
USB_Descriptor_String_t PROGMEM ManufacturerString =
{
.Header = {.Size = USB_STRING_LEN(3), .Type = DTYPE_String},
.UnicodeString = L"JRT"
};
USB_Descriptor_String_t PROGMEM ProductString =
{
.Header = {.Size = USB_STRING_LEN(13), .Type = DTYPE_String},
.UnicodeString = L"Micro Storage"
};
You’ll also need a descriptor that enumerates your interfaces and endpoints. Seeing as this is specific to your project, and C is a significantly limited language, you’ll need to make a quick structure declaration then fill that structure:
typedef struct {
USB_Descriptor_Configuration_Header_t Config;
USB_Descriptor_Interface_t Interface;
USB_Descriptor_Endpoint_t DataInEndpoint;
USB_Descriptor_Endpoint_t DataOutEndpoint;
USB_Descriptor_Endpoint_t CommandEndpoint;
} USB_Descriptor_Configuration_t;
USB_Descriptor_Configuration_t PROGMEM ConfigurationDescriptor =
{
.Config =
{
.Header = {.Size = sizeof(USB_Descriptor_Configuration_Header_t), .Type = DTYPE_Configuration},
.TotalConfigurationSize = sizeof(USB_Descriptor_Configuration_t),
.TotalInterfaces = 1,
.ConfigurationNumber = 1,
.ConfigurationStrIndex = NO_DESCRIPTOR,
.ConfigAttributes = USB_CONFIG_ATTR_BUSPOWERED,
.MaxPowerConsumption = USB_CONFIG_POWER_MA(100)
},
.Interface =
{
.Header = {.Size = sizeof(USB_Descriptor_Interface_t), .Type = DTYPE_Interface},
.InterfaceNumber = 0,
.AlternateSetting = 0,
.TotalEndpoints = 3,
.Class = 0xff,
.SubClass = 0xaa,
.Protocol = 0x0,
.InterfaceStrIndex = NO_DESCRIPTOR
},
.DataInEndpoint =
{
.Header = {.Size = sizeof(USB_Descriptor_Endpoint_t), .Type = DTYPE_Endpoint},
.EndpointAddress = (ENDPOINT_DESCRIPTOR_DIR_IN | BULK_IN_EPNUM),
.Attributes = (EP_TYPE_BULK | ENDPOINT_ATTR_NO_SYNC | ENDPOINT_USAGE_DATA),
.EndpointSize = BULK_IN_EPSIZE,
.PollingIntervalMS = 0x00
},
.DataOutEndpoint =
{
.Header = {.Size = sizeof(USB_Descriptor_Endpoint_t), .Type = DTYPE_Endpoint},
.EndpointAddress = (ENDPOINT_DESCRIPTOR_DIR_OUT | BULK_OUT_EPNUM),
.Attributes = (EP_TYPE_BULK | ENDPOINT_ATTR_NO_SYNC | ENDPOINT_USAGE_DATA),
.EndpointSize = BULK_OUT_EPSIZE,
.PollingIntervalMS = 0x00
},
.CommandEndpoint =
{
.Header = {.Size = sizeof(USB_Descriptor_Endpoint_t), .Type = DTYPE_Endpoint},
.EndpointAddress = (ENDPOINT_DESCRIPTOR_DIR_OUT | COMMAND_EPNUM),
.Attributes = (EP_TYPE_BULK | ENDPOINT_ATTR_NO_SYNC | ENDPOINT_USAGE_DATA),
.EndpointSize = COMMAND_EPSIZE,
.PollingIntervalMS = 0x00
}
};
So now you see I have a device with a single interface and three bulk endpoints (two OUT and one IN). Remember, in USB terminology OUT means from the HOST to the GADGET while IN means from the GADGET to the HOST. While there is a direction to these channels, USB 1.0 and 2.0 BULK communications start with the host sending a message to the device (i.e. IN endpoints are polled) and the device should always respond. Now that we have descriptors lets be sure to send them when the host tries to enumerate the device.
uint16_t CALLBACK_USB_GetDescriptor
(const uint16_t wValue,
const uint8_t wIndex,
void **const DescriptorAddress)
{
const uint8_t DescriptorType = (wValue >> 8);
const uint8_t DescriptorNumber = (wValue & 0xFF);
void* Address = NULL;
uint16_t Size = NO_DESCRIPTOR;
switch (DescriptorType) {
case DTYPE_Device:
Address = (void*)&DeviceDescriptor;
Size = sizeof(USB_Descriptor_Device_t);
break;
case DTYPE_Configuration:
Address = (void*)&ConfigurationDescriptor;
Size = sizeof(USB_Descriptor_Configuration_t);
break;
case DTYPE_String:
switch (DescriptorNumber) {
case 0x00:
Address = (void*)&LanguageString;
Size = pgm_read_byte(&LanguageString.Header.Size);
break;
case 0x01:
Address = (void*)&ManufacturerString;
Size = pgm_read_byte(&ManufacturerString.Header.Size);
break;
case 0x02:
Address = (void*)&ProductString;
Size = pgm_read_byte(&ProductString.Header.Size);
break;
}
break;
}
*DescriptorAddress = Address;
return Size;
}
With this, and calling USB_Init() when your device starts up, you should have a gadget that is properly enumerated by the matching driver. Once a configuration is selected we need to configure the endpoints, but after that we can finally send and receive data!
void EVENT_USB_Device_ConfigurationChanged(void)
{
int i,succ=1;
succ &= Endpoint_ConfigureEndpoint(BULK_IN_EPNUM, EP_TYPE_BULK, ENDPOINT_DIR_IN,
BULK_IN_EPSIZE, ENDPOINT_BANK_SINGLE);
succ &= Endpoint_ConfigureEndpoint(BULK_OUT_EPNUM, EP_TYPE_BULK, ENDPOINT_DIR_OUT,
BULK_OUT_EPSIZE, ENDPOINT_BANK_SINGLE);
succ &= Endpoint_ConfigureEndpoint(COMMAND_EPNUM, EP_TYPE_BULK,
ENDPOINT_DIR_OUT, COMMAND_EPSIZE,
ENDPOINT_BANK_SINGLE);
LED_CONFIG;
while(!succ) {
LED_ON;
_delay_ms(1000);
LED_OFF;
_delay_ms(1000);
}
for(i = 0; i < 5; i ++) {
LED_ON;
_delay_ms(50);
LED_OFF;
_delay_ms(50);
}
}
Now to handle any data on the endpoints, you’ll probably want to tight loop around code that checks each endpoint, reads data, and performs some action:
if (USB_DeviceState != DEVICE_STATE_Configured)
return;
Endpoint_SelectEndpoint(BULK_IN_EPNUM);
if (Endpoint_IsConfigured() && Endpoint_IsINReady() && Endpoint_IsReadWriteAllowed()) {
do_something(state, data, &len);
err = Endpoint_Write_Stream_LE((void *)data, len);
// FIXME handle err
Endpoint_ClearIN();
}
Endpoint_SelectEndpoint(BULK_OUT_EPNUM);
if (Endpoint_IsConfigured() && Endpoint_IsOUTReceived() && Endpoint_IsReadWriteAllowed()) {
err = Endpoint_Read_Stream_LE(data, len);
do_other_thing(data, len);
Endpoint_ClearOUT();
}
Endpoint_SelectEndpoint(COMMAND_EPNUM);
if (Endpoint_IsConfigured() && Endpoint_IsOUTReceived() && Endpoint_IsReadWriteAllowed()) {
usb_cmd_t cmd;
err = Endpoint_Read_Stream_LE(&cmd, sizeof(usb_cmd_t));
update_state(cmd);
Endpoint_ResetFIFO(BULK_IN_EPNUM);
Endpoint_ResetFIFO(BULK_OUT_EPNUM);
Endpoint_ClearOUT();
}
And that’s the whole deal. Some things to take note of:
1) I don’t know why I needed Endpoint_ResetFIFO() – my results lagged by one message without them but I feel certain this is not the correct way to fix the issue. Perhaps I need to reset the endpoints some time after configuration and before use, but I’m not sure which callback to use for that, if that’s the case.
2) C needs phantom types. Many of these functions aren’t intended for use with CONTROL endpoints. See the LUFA documentation for which functions to use if you have non-BULK endpoints.
3) Be sure to number your ENDPOINTS starting at 1 (the *_EPNUM values). I’ve seen unusual behavior when numbering started higher – not sure if that was against standards or not.
Conclusion
At a minimum, you must declare a “USB_Descriptor_Device_t” variable, three “USB_Descriptor_String_t” variables (Language, Manufacturer, Product), a custom “USB_Descriptor_Configuration_t” structure and variable. Also declare a function named “CALLBACK_USB_GetDescriptor” and one called “EVENT_USB_Device_ConfigurationChanged(void)” which calls
“Endpoint_ConfigureEndpoint(*_EPNUM, EP_TYPE_{BULK, INT, CONTROL, ISOC}, ENDPOINT_DIR_{IN,OUT}, *_EPSIZE, ENDPOINT_BANK_{DOUBLE,SINGLE});” for each endpoint in the configuration. Finally use “Endpoint_SelectEndpoint(*_EPNUM)” followed by “Endpoint_Is{INReady,OutReceived}() && Endpoint_IsReadWriteAllowed()” to select an endpoint and check for data. Finish all this by reading your stream “Endpoint_Read_Stream_LE(buf, len)” and issue a call to “Endpoint_Clear{IN,OUT}()” when done.
HacPDX is Coming
September 19, 2009
That’s right – HacPDX is less than a week away so REGISTER if you haven’t. Failure to register means you might not have network access or even a chair!
I’ve planned to work on networking but I’ll be happy to work on anything that interests people and makes progress including networking, crypto, kernel modules, hackage-server, even ARM (assuming an expert attends).
I’ve also heard a number of people mention working on various C Bindings – which is awesome because I suck at marshalling so maybe they can help. Can’t wait to see everyone there and hacking away!
Explicit Parallelism via Thread Pools
March 13, 2009
I’m happy to say that this post is being finished up from my new home in Portland, Oregon! After many years of searching around I’ve finally decided to study at Portland State. Its probably optimisitic of me to think I’ll have more time as a graduate student, but I hope this is the beginning of much more involvement for me in the Haskell community.
Thread Pools from the Control-Engine Package
Control.Engine was recently released on hackage, providing a simple way to instantiate worker threads to split-up the processing of streaming data. Its was originally developed as a spin-off library from my DHT and I’ve since generalized it to cover numerous cases.
Trivial Thread Pools
The trivial module Control.ThreadPool can cover static examples such as a recent question asked on the haskell-cafe:
I have a function that does some IO (takes a file path, read the file, parse, and return some data), and I would like to parallelize it, so that multiple files can be parsed in parallel.
‘Control.ThreadPool’ gives us an easy answer (but not as slick as the map reduce answer the person was asking for on cafe). First we have our typical fluff.
import Control.ThreadPool (threadPoolIO)
import System.IO (openFile, IOMode(..))
import System.Environment (getArgs)
import Control.Concurrent.Chan
import Control.Monad (forM_)
import qualified Data.ByteString.Lazy.Char8 as L
main = do
as <- getArgs
As you can see below, we simply say how many threads we want in our thread pool and what action (or pure computation, using ‘threadPool’) we wish to perform. After that its just channels – send input in and read results out!
(input,output) <- threadPoolIO nrCPU op mapM_ (writeChan input) as -- input stream forM_ [1..length as] (\_ -> readChan output >>= print) where nrCPU = 4 op f = do h <- openFile f ReadMode c <- L.hGetContents h let !x = length . L.words $ c hClose h return (f,x)
And while this does nothing to demonstrate paralellism, it does work:
[tom@Mavlo Test]$ ghc -O2 parLines.hs --make -threaded -fforce-recomp
[1 of 1] Compiling Main ( web.hs, web.o )
Linking web ...
[tom@Mavlo Test]$ find ~/dev/Pastry -name *lhs | xargs ./parLines +RTS -N4 -RTS
("/home/tom/dev/Pastry/Network/Pastry/Module/Joiner.lhs",107)
("/home/tom/dev/Pastry/Network/Pastry/Config.lhs",14)
("/home/tom/dev/Pastry/Network/Pastry/Data/LeafSet.lhs",120)
("/home/tom/dev/Pastry/Network/Pastry/Data/Router.lhs",87)
("/home/tom/dev/Pastry/Network/Pastry/Data/RouteTable.lhs",75)
("/home/tom/dev/Pastry/Network/Pastry/Data/Address.lhs",152)
Control Engine Setup
The thread pools are simple, but what if you need more flexibility or power? What happens if you want to have an up-to-date state shared amoung the threads, or there’s a non-paralizable cheap computation you need to perform before the main operation? The answer is to use Control.Engine instead of Control.ThreadPool. The engine provides managed state, numerous hook location, and an abilty to inject information to mid-engine locations.
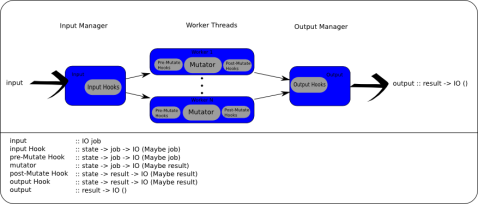
Injectors
The inject* calls can bypass the input hooks (injectPreMutator) or bypass everything besides the output hooks (injectPostMutator) – thus creating a ‘result’ that had no corrosponding ‘job’.
Hooks
Hooks are capable of modifying or filtering jobs or results. All hooks are of type state -> a -> IO (Maybe a); its important to note the type can not change and if a hook returns Nothing then the job or result stops there.
Hooks can either be input, pre-mutate, post-mutate, or output. Input and output hooks are ran in series on all jobs or results respectivly; this is intended for low computation tasks that shouldn’t be done in parallel later. Pre and post mutate hooks happen on the (parallel) worker threads before an after the main task, called the mutator.
Mutator
The engine consists of N mutator threads, which is the only operation capable of transforming the jobs into a different (result) type.
State Management
Control.Engine was built with the idea that jobs and state reads were frequent while alterations to the state were rare. A design decision was made to use STM to resolve all contention on state alterations and have a manager watch the TVar for change then bundle those changes in a quicker to read fashion (MVar) for the input, output, and worker threads.
The state provided to the hooks and mutator is always consistent but not guarenteed up-to-date. When modifications to the state occur a transactional variable is modified, which wakes the stateManager; in turn, the state manager updates the state MVar which is read by each thread before processing the next job. In the future IORefs might be used instead of the MVar – all contention is handled by the STM and the only writer for the MVar (future IORef) should be the State Manager.
Web Crawling
Now lets figure out how to help users who need more flexibility using Control.Engine instead of Control.ThreadPool.
MyCatVerbs, from #haskell, suggested a web crawler that uses URls as the job and the mutator (worker) can add all the links of the current page as new jobs while ignoring any URL that was already visited. Lets start!
The imports aren’t too surprising – tagsoup, concurrent, bloomfilter and Control-Engine are the packages I draw on.
module Main where import Control.Concurrent (forkIO, threadDelay) import Control.Concurrent.Chan import Control.Monad (forever, when) import Control.Engine -- Control-Engine import Control.Exception as X import Data.BloomFilter -- bloomfilter import Data.BloomFilter.Hash -- bloomfilter import Data.BloomFilter.Easy -- bloomfilter import Data.IORef import System.Environment (getArgs) import Text.HTML.Download -- tagsoup import Text.HTML.TagSoup -- tagsoup type URL = String data Job = GetURL URL | ParseHTML URL String deriving (Eq, Ord, Show) main = do (nrCPU:url:_) <- getArgs
The library tries to remain flexible which makes you do a little more work but don’t let that scare you! It needs an IO action to get tasks and an IO action that delivers the results. Most people will probably just want a channel, but sockets or files would do just as well.
input <- newChan output <- newChan
Starting the engine is a one line affair. You provide the number of threads, input, output, a mutator function and initial state. In return you are provided with an ‘Engine’ with which you can modify the hooks and use the injection points.
For this web crawler my ‘state’ is just a bloom filter of all visited URLs so I’ll keep that in the one hook its needed and declare the engine-wide state as a null – (). For the chosen task the mutator needs a way to add more jobs (more URLs) so as pages are parsed any new URLs can be queued for future crawling; this is handled via partial application of mutator funciton.
eng <- initEngine (read nrCPU) (readChan input) (writeChan output) (mutator (writeChan input)) ()
As mentioned, I’ll use a bloom filter to keep the web crawler from re-visiting the same site many times. This should happen exactly once for each URL and is fairly fast so I’ll insert it as an ‘Input Hook’ which means a single thread will process all jobs before they get parsed out to the parallel thread pool.
let initialBF = fromListB (cheapHashes nrHashes) nrBits []
(nrBits, nrHashes) = suggestSizing 100000 (10 ** (-6))
bf <- newIORef (initialBF,0)
let bfHook = Hk (uniqueURL bf) 1 "Ensure URLs have not already been crawled"
addInputHook eng bfHook
Finishing up main, we print all results then provide an initial URL. Notice we run forever – there’s no clean shutdown in this toy example.
forkIO $ forever $ printResult output writeChan input (GetURL url) neverStop eng where neverStop eng = forever $ threadDelay maxBound
And from here on we’re just providing the worker routine that will run across all the threads and we’ll define the input hook. TagSoup performs all the hard work of downloading the page and parsing HTML. Just pull out the <a href=”…”> tags to add the new URLs as jobs before returning any results. In this example I decided to avoid any sort of error checking (ex: making sure this is an HTML document) and simply returning the number of words as a result.
mutator :: (Job -> IO ()) -> st -> Job -> IO (Maybe (URL,Int)) mutator addJob _ (GetURL url) = forkIO (do e <- X.try (openURL url) :: IO (Either X.SomeException String) case e of Right dat -> addJob (ParseHTML url dat) _ -> return () ) >> return Nothing mutator addJob _ (ParseHTML url dat) = do let !urls = getURLs dat !len = length urls fixed = map (\u -> if take 4 u /= "http" then url ++ '/' : u else u) urls mapM_ (addJob . GetURL) fixed return $ Just (url,len) where getURLs :: String -> [URL] getURLs s = let tags = parseTags s in map snd (concatMap hrefs tags) hrefs :: Tag -> [(String,String)] hrefs (TagOpen "a" xs) = filter ( (== "href") . fst) xs hrefs _ = [] printResult :: (Show result) => Chan result -> IO () printResult c = readChan c >>= print
Filtering out non-unique URLs is just the bloom filter in action.
uniqueURL :: IORef (Bloom URL, Int) -> st -> Job -> IO (Maybe Job)
uniqueURL _ _ j@(ParseHTML _ _) = return $ Just j
uniqueURL bf _ j@(GetURL url) = do
(b,i) <- readIORef bf
if elemB url b
then putStrLn ("Reject: " ++ url) >> return Nothing
else do writeIORef bf (insertB url b, i + 1)
when (i `rem` 100 == 0) (print i)
return $ Just j
Performance
P.S. No serious performance measurements have been made beyond extremely expensive (and trivially parallel) problems, so those don’t count.
14Mar2009 EDIT: Said something about Control.Engine before showing the diagram to make reading smoother.
EDIT2: ThreadPool example shown was a version using MD5, not length – oops! Fixed now.
hsXenCtrl and pureMD5
August 7, 2008
On vacation I found some time to upload the new hsXenCtrl library (0.0.7) and pureMD5 (0.2.4)
The new hsXenCtrl includes the System.Xen module, which is a WriterT ErrorT transformer stack and a brief attempt at ‘Haskellifying’ the xen control library. I find it much more useful for simple tasks like pausing, unpasing, creating and destroying domains. The API is still subject to change without notice as plenty of function are still very ‘C’ like (ex: scheduler / sedf functions).
pureMD5 received a much smaller change – some users noticed the -fvia-c caused compilation headaches on OS X. After removing the offending flag, some benchmarks revealed no measureable difference in speed, so this is an over-due change. OS X users rejoice!
Objections to Lenovo + SuSE
June 10, 2008
I just received my Thinkpad T61p and was eager to try SUSE, seeing as I have never used SUSE before but have used about every other major Linux distribution. Sadly it didn’t pan out:
1) Updating the software via zmd
Sat for over half an hour “resolving dependencies” without telling me anything else (buttons were grayed out). Sorry, but rule number one: never leave the user out of the loop.
2) Installing a basic -devel library (libpng, depends on zlib):
resolve-dependency: 50 sec
transact: 54 sec
update-status: 49 sec
And when I add in zmd updating the list of software, I am talking about a three or four minute process just to install trivial developer libraries such as libpng-devel. I’m sure this is just a configuration issue but it really gave me a sour taste.
3) Using Yast2
A) Common libraries and programs not in SUSEs repo
Many packages weren’t even found, for example ‘wine’ and ‘libjpeg-devel’ turned up zero search results. Perhaps there is some reason the GUI isn’t giving me much, but using yast through the cli doesn’t seem to be any comparison to apt or yum. Am I mistaken in thinking yast2 should help here?
B) Many options not entirely visible
“Installation into Dire” ok, so I know thats “Directory”, but what does it do? Can it help with any of my issues? Why can’t I mouse over it and read it all or see the entire text in a status bar?
4) Upgrading to 10.1 and 10.2
A) Three was no blatant ‘upgrade to 10.1’ button, but I found it and lived, no big deal
B) Upgrading to 10.2, short of downloading openSUSE DVDs, seems to require registration. This is amazingly stupid if so. Even if there is a way to do so without registering why have the road block method be the easiest one to stumble across (via yast2 -> online update)?
C) Registration requires a “Service Tag” which probably came with my laptop (or could it be that I am not entitled to this service?). Being a savvy computer user I know right where to look for service tag numbers… after trying numbers on the laptop, the CD, the CD sleeve, and some on the box I gave up (I couldn’t find any documentation that identified such a number, obviously).
What does all this mean to the average Troll Enthusiast Fanatic Open-source-developer-wanna-be Parasite (TEFOP)?
1) I’m too tired
2) I don’t know how to use SuSE (and don’t care enough to spend much time)
3) My Internet connection must be mush (nope, I’ve been getting 200KBps, all of my HTTP downloads were fine)
And what do I want you to take away?
1) Hardware vendors shouldn’t ship 3 year old OSes (10.0 came out 6Oct2005)
2) More importantly: Software vendors trying to improve on their brand name should not allow older versions of their product to continue shipping on new hardware!
3) Requiring registration is a bad idea, but if it must be so then tell customers where to get the information you are requesting of them.
4) Keep the user informed. I don’t like 4 minute install times for 400KB libraries. I literally found the homepage, downloaded, compiled and installed a program before my single package install finished in two cases.
Business Models and Open Source
April 6, 2008
I’ve always thought the ideal work would include a healthy dose of open source. To this end, I try to make my time wasting activities (slashdot, proggit) worth while by noting the various business models and their success. This is an informal brain dump with extra facts pulled in from Wikipedia – as such you should confirm any information before long term storage in your brain.
For idealistic reasons, the preferred model would be like RedHats. You compose, improve and build open source projects and products, providing them for free and selling the service (consulting, tailored development, support).
The main problem here is that, as a theoretical small business owner, I want to sell products and not services. In addition to the the discreet nature of products (as opposed to continuing duties of services), the constructive feel of a product oriented business seems nice in contrast to the droning of a service oriented business. Here is a question: is the concept of open source at odds with product driven revenue?
The Xen method seemed to be making an open source component and selling closed source support tools. This appeared aimed at preventing RedHat et al. from ‘stealing’ the GPL code and owing nothing to XenSource. I say “seemed” because the true aim could have been to get bought out – as XenSource was on 22Oct2007 by Citrix for $500M.
A well known (and often successful) method of dual licensing was employed by TrollTech. TrollTech owned the source to QT which they monotized by selling proprietary licenses in addition to offering the source code under GPL. Like Citrix, on 28Jan2008 Nokia offered (and TrollTech accepted) a $163M buyout.
Like TrollTech, MySQL offered both support and dual licensing. I notice this is referred to as a ‘second generation’ open source company on Wikipedia – not sure how common this term is, but I take issue with the idea that the distinguishing factor between second and first generation open source companies is their ability/willingness to sell closed source licenses. MySQL was purchased by SUN on 16Feb08 for $1B… are we seeing a trend yet?
The Jabberwolk
March 21, 2008
Welcome to the Jabberwolk. This is my blog recently moved from sequence.complete.org. Here I will try to stay on the topics of Haskell, Xen, and Linux but anything technical is game and I’ll warn you that politics might appear (but I’ll try to keep that down).
Edit: My old blog is here.
