Crypto-API Released
September 7, 2010
Crypto-API (hackage, haddock) 0.0.0.1 is now on Hackage.
Crypto-API is a generic interface for cryptographic operations, platform independent quality Entropy, property tests and known-answer tests (KATs) for common algorithms, and a basic benchmark infrastructure. Maintainers of hash and cipher implementations are encouraged to add instances for the classes defined in Crypto.Classes. Crypto users are similarly encouraged to use the interfaces defined in the Classes module.
Previous blogs on crypto-api have discussed its design and the RNG interface. These were to aid design discussion, so note the code there won’t work without minor changes.
Example: Hashes
An example class instance:
instance Hash MD5Context MD5Digest where
outputLength = Tagged 128
blockLength = Tagged 512
initialCtx = md5InitialContext
updateCtx = md5Update
finalize = md5Finalize
The hash user can remain agnostic about which type of hash is used:
authMessage :: Hash ctx dgst => B.ByteString -> MacKey -> dgst -> Bool authMessage msg k = (==) (hmac' k msg) hashFile :: Hash c d => FilePath -> IO d hashFile = liftM hash L.readFile
Example: Block Cipher
Users of block cipher instances probably want to use Crypto.Modes:
import Crypto.Classes
import Crypto.Modes (cbc)
import Data.Serialize (encode)
cipherMsgAppendIV :: (BlockCipher k) => k -> B.ByteString -> IO B.ByteString,
cipherMsgAppendIV msg = do
iv <- getIVIO
return $ B.append (encode iv) (cbc k iv msg)
Example RNG
Its easy to get a DRBG (aka PRNG) that can be used for generating seed material for keys, building asymmetric keys, obtaining initialization vectors, nonces, or many other uses. See Crypto.Random (which users System.Crypto.Random for entropy):
newGenIO :: CryptoRandomGen g => IO g genBytes :: (CryptoRandomGen g) => g -> ByteLength -> Either GenError (ByteString, g) getIV :: (CryptoRandomGen g, BlockCipher k) => g -> Either GenError (IV k, g) buildKeyPair :: CryptoRandomGen g => g -> BitLength -> Maybe ((p, p), g)
Tests
A quick peek in the Test.Crypto module will show you that testing is decent (particularly for AES) and getting better all the time.
Given a BlockCipher instance the entire test code for an AES implementation is:
-- Omitting hack-job instances for SimpleAES in this snippet
main = do
ts <- makeAESTests (AESKey $ B.replicate 16 0)
runTests ts
This automatically reads in hundreds of NIST Known Answer Tests (KATs) and checks the implementation. A lesser infrastructure exists for testing Hashes. Cipher property tests are still needed.
Example: Benchmarking
As with tests, benchmarking is quite simple:
import Data.Digest.Pure.MD5 import Benchmark.Crypto import Criterion.Main main = defaultMain [benchmarkHash (undefined :: MD5Digest) "pureMD5"]
Closing
So please, if you maintain a hash, cipher, or other cryptographic primitive please add instances for the crypto-api classes. If you need these primitives then consider using the crypto-api interfaces, allowing you to remain algorithm and implementation agnostic in all your low level code.
A Better Foundation for Random Values in Haskell
September 2, 2010
RandomGen – The Old Solution
Mathematicians talk about random bits and many programmers talk about streams of random bytes (ex: /dev/urandom, block cipher counter RNGs), so its a bit odd that Haskell adopted the RandomGen class, which only generates random Ints. Several aspects of RandomGen that are non-ideal include:
- Only generates Ints (Ints need to be coerced to obtain other types)
- By virtue of packaging it is often paired with StdGen, a sub-par generator
- Mandates a ‘split’ operation, which is non-sense or unsafe for some generators (as BOS pointed out in a comment on my last post)
- Doesn’t allow for generator failure (too much output without a reseed) – this is important for cryptographically secure RNGs
- Doesn’t allow any method for additional entropy to be included upon request for new data (used at least in NIST SP 800-90 and there are obvious default implementations for all other generators)
Building Something Better
For these reasons I have been convinced that building the new crypto-api package on RandomGen would be a mistake. I’ve thus expanded the scope of crypto-api to include a decent RandomGenerator class. The proposal below is slightly more complex than the old RandomGen, but I consider it more honest (doesn’t hide error conditions / necessitate exceptions).
class RandomGenerator g where
-- |Instantiate a new random bit generator
newGen :: B.ByteString -> Either GenError g
-- |Length of input entropy necessary to instantiate or reseed a generator
genSeedLen :: Tagged g Int
-- |Obtain random data using a generator
genBytes :: g -> Int -> Either GenError (B.ByteString, g)
-- |'genBytesAI g i entropy' generates 'i' random bytes and use the
-- additional input 'entropy' in the generation of the requested data.
genBytesAI :: g -> Int -> B.ByteString -> Either GenError (B.ByteString, g)
genBytesAI g len entropy =
... default implementation ...
-- |reseed a random number generator
reseed :: g -> B.ByteString -> Either GenError g
Compared to the old RandomGen class we have:
- Random data comes in Bytestrings. RandomGen only gave Ints (what is that? 29 bits? 32 bits? 64? argh!), and depended on another class (Random) to build other values. We can still have a ‘Random’ class built for RandomGenerator – should we have that in this module?
- Constructing and reseeding generators is now part of the class.
- Splitting the PRNG is now a separate class (not shown)
- Generators can accept additional input (genBytesAI). Most generators probably won’t use this, so there is a reasonable default implementation (fmap (xor additionalInput) genBytes).
- The possibility to fail – this is not new! Even in the old RandomGen class the underlying PRNGs can fail (the PRNG has hit its period and needs a reseed to avoid repeating the sequence), but RandomGen gave no failure mechanism. I feel justified in forcing all PRNGs to use the same set of error messages because many errors are common to all generators (ex: ReseedRequred) and the action necessary to fix such errors is generalized too.
In Closing
The full Data.Crypto.Random module is online and I welcome comments, complaints and patches. This is the class I intend to force users of the Crypto API block cipher modes and Asymmetric Cipher instances to use, so it’s important to get right!
GHC on ARM
January 19, 2010
During my “Linux Kernel Modules with Haskell” tech talk I mentioned my next personal project (on my already over-full plate) would be to play with Haskell on ARM. I’m finally getting around to a little bit of playing! Step zero was to get hardware so I acquired a touchbook – feel free to ignore all the marketing on that site (though I am quite happy with it) and just understand it is the equivalent of a beagleboard with keyboard, touch-pad, touch screen, speakers, wifi, bluetooth, two batteries, more USB ports, and a custom Linux distribution.
Step 1: Get an Unregistered Build
To start its best to bypass the porting GHC instructions and steal someone elses porting effort in the form of a Debian package (actually, three debian packages). Convert them to a .tar.gz (unless you have a debian OS on your ARM system) using a handy deb2targz script. Now untar them onto your ARM system via “sudo tar xzf oneOfThePackages.tar.gz -C /” . Be sure to copy the package.conf as it seems to be missing from the .debs “sudo cp /usr/lib/ghc-6.10.4/package.conf.shipped /var/lib/ghc-6.10.4/package.conf”. After all this you should have a working copy of GHC 6.10.4 – confirm that assertion by compiling some simple test programs.
I now have my copy of 6.10.4 building GHC 6.12.1. The only hitch thus far was needing to add -mlong-calls to the C options when running ./configure. With luck I will soon have an unregistered GHC 6.12.1 on my ARM netbook. I’ll edit this post tomorrow with results (yes, I’m actually compiling on the ARM and not in an x86 + QEMU environment).
Step 2: Get a registered build – upstream patches
This is where things become more black-box to me. I want to make a native code generator (NCG) for GHC/ARM. There are some decent notes about the RTS at the end of the previously mentioned porting guide and there is also a (up-to-date?) page on the NCG. Hopefully this, combined with the GHC source, will be enough but I’ll probably be poking my head into #ghc more often.
Step 3: Write more Haskell
The purpose of all of this was to use Haskell on my ARM system. Hopefully I’ll find time to tackle some problems that non-developers will care about!
HacPDX is Coming
September 19, 2009
That’s right – HacPDX is less than a week away so REGISTER if you haven’t. Failure to register means you might not have network access or even a chair!
I’ve planned to work on networking but I’ll be happy to work on anything that interests people and makes progress including networking, crypto, kernel modules, hackage-server, even ARM (assuming an expert attends).
I’ve also heard a number of people mention working on various C Bindings – which is awesome because I suck at marshalling so maybe they can help. Can’t wait to see everyone there and hacking away!
Kernel Modules in Haskell
September 13, 2009
If you love Haskell and Linux then today is your day – today we reconcile the two and allow you to write Linux Kernel modules in Haskell. By making GHC and the Linux build system meet in the middle we can have modules that are type safe and garbage collected. Using the copy of GHC modified for the House operating system as a base, it turns out to be relatively simple to make the modifications necessary to generate object files for the Kernel environment. Additionally, a new calling convention (regparm3) was added to make it easier to import (and export) functions from the Kernel.
EDIT: I’m getting tired of updating this page with extremely minor changes and having it jump to the top of planet.haskell.org, so for the latest take a look at the haskell wiki entry. It includes discussion of the starting environment – a pretty large omission from the original post.
Starting Environment
You need a Linux x86 (not AMD64) based distribution with GCC 4.4 or higher and recent versions of gnu make and patch along with many other common developer tools usually found in a binutils package (e.g. ar, ld). You also should have the necessary tools to build GHC 6.8.2 – this includes a copy of ghc-6.8.x, alex, and happy.
Building GHC to Make Object files for Linux Modules
Start by downloading the House 0.8.93 [1]. Use the build system to acquire ghc-6.8.2 and apply the House patches. The House patches allow GHC to compile Haskell binaries that will run on bare metal (x86) without an underlying operating system, so this makes a good starting point.
> wget http://web.cecs.pdx.edu/~kennyg/house/House-0.8.93.tar.bz2 > tar xjf House-0.8.93.tar.bz2 > cd House-0.8.93 > make boot > make stamp-patch
Now acquire the extra patch which changes the RTS to use the proper Kernel calls, instead of allocating its own memory, and to respect the current interrupt level. This patch also changes the build options to avoid common area blocks for uninitilized data (-fno-common) and use frame pointers (-fno-omit-frame-pointers).
> wget https://projects.cecs.pdx.edu/~dubuisst/hghc.patch
> patch -d ghc-6.8.2 -p1 < hghc.patch
> make stamp-configure
> make stamp-ghc # makes ghc stage 1
Next, build a custom libgmp with the -fno-common flag set. This library is needed for the Integer support in Haskell.
> wget ftp://ftp.gnu.org/gnu/gmp/gmp-4.3.1.tar.bz2 > tar xjf gmp-4.3.1.tar.bz2 > cd gmp-4.3.1 > ./configure # edit 'Makefile' and add '-fno-common' to the end of the 'CFLAGS = ' line. > make > cp .libs/libgmp.a $HOUSE_DIR/support
Apply ‘support.patch’ to alter the build systems of the libtiny_{c,gcc,gmp}.a and build the libraries.
> wget https://projects.cecs.pdx.edu/~dubuisst/support.patch > patch -p0 -d $HOUSE_DIR < support.patch > make -C $HOUSE_DIR/support
Build the cbits object files:
> make -C $HOUSE_DIR/kernel cobjs
In preparation for the final linking, which is done manually, pick a working directory ($WDIR) that will serve to hold the needed libraries. Make some last minute modifications to the archives and copy libHSrts.a, libcbits.a, libtiny_gmp.a, libtiny_c.a, and libtiny_gcc.a
> mkdir $WDIR
> ar d support/libtiny_c.a dlmalloc.o # dlmalloc assumes it manages all memory
> ar q $WDIR/libcbits.a kernel/cbits/*.o
> cp ghc-6.8.2/rts/libHSrts.a support/libtiny_{c,gcc,gmp}.a $WDIR
Build a Kernel Module
First, write the C shim that will be read by the Linux build system. While it might be possible to avoid C entirely its easier to use the build system, and its plethora of macros, than fight it. The basic components of the shim are a license declaration, function prototypes for the imported (Haskell) functions, initialization, and exit functions. All these can be seen in the example hello.c [2].
Notice that many of the standard C functions in the GHC RTS were not changed by our patches. To allow the RTS to perform key actions, such as malloc and free, the hello.c file includes shim functions such as ‘malloc’ which simply calls ‘kmalloc’. Any derivative module you make should include these functions either in the main C file or a supporting one.
Second, write a Haskell module and export the initialization and exit function so the C module may call them. Feel free to import kernel functions, just be sure to use the ‘regparm3’ key word in place of ‘ccall’ or ‘stdcall’. For example:
foreign import regparm3 unsafe foo :: CString -> IO CInt foreign export regparm3 hello :: IO CInt
Continuing the example started by hello.c, ‘hsHello.hs’ is online [3].
Now start building the object files. Starting with building hsHello.o, you must execute:
> $HOUSE_DIR/ghc-6.8.2/compiler/stage1/ghc-inplace -B$HOUSE_DIR/ghc-6.8.2 hsHello.hs -c
* note that this step will generate or overwrite any hsHello_stub.c file.
When GHC generates C code for exported functions there is an implicit assumption that the program will be compiled by GHC. As a result the nursery and most the RTS systems are not initialized so the proper function calls must be added to hsHello_stub.c.
Add the funcion call “startupHaskell(0, NULL, NULL);” before rts_lock() in the initializing Haskell function. Similarly, add a call to “hs_exit_nowait()” after rts_unlock().
The stub may now be compiled, producing hsHello_stub.o. This is done below via hghc, which is an alias for our version of ghc with many flags [4].
> hghc hsHello_stub.c -c
The remaining object files, hello.o and module_name.mod.o, can be created by the Linux build system. The necessary make file should contain the following:
obj-m := module.o # Obviously you should name the module as you see fit module-objs := hello.o
And the make command (assuming the kernel source is in /usr/src/kernels/):
> make -C /usr/src/kernels/2.6.29.6-217.2.16.fc11.i586 M=`pwd` modules
This should make “hello.o” and “module.mod.o”. Everything can now be linked together with a single ld command.
> ld -r -m elf_i386 -o module.ko hsHello_stub.o hsHello.o module.mod.o hello.o *.a libcbits.a
A successful build should not have any common block variables and the only undefined symbols should be provided by the kernel, meaning you should recognize said functions. As a result, the first command below should not result in output while the second should be minimal.
> nm module.ko | egrep “^ +C ” > nm module.ko | egrep “^ +U ” U __kmalloc U kfree U krealloc U mcount U printk
Known Issue
The House-GHC 6.8.2 run-time system (RTS) does not clean up the allocated memory on shutdown, so adding and removing kernel modules results in large memory leaks which can eventually crash the system. This should be relatively easy to fix, but little investigation was done.
A good estimate of the memory leak is the number of megabytes in the heap (probably 1MB, unless your module needs lots of memory) plus 14 bytes of randomly leaked memory from two unidentified (6 and 8 byte) allocations.
[1] http://web.cecs.pdx.edu/~kennyg/house/
[2] https://projects.cecs.pdx.edu/~dubuisst/hello.c
[3] https://projects.cecs.pdx.edu/~dubuisst/hsHello.hs
[4] $HOUSE_DIR/ghc-6.8.2/compiler/stage1/ghc-inplace -B$HOUSE_DIR/ghc-6.8.2 -optc-fno-common -optc-Wa,symbolic -optc-static-libgcc -optc-nostdlib -optc-I/usr/src/kernels/2.6.29.6-213.fc11.i586/arch/x86/include/ -optc-MD -optc-mno-sse -optc-mno-mmx -optc-mno-sse2 -optc-mno-3dnow -optc-Wframe-larger-than=1024 -optc-fno-stack-protector -optc-fno-optimize-sibling-calls -optc-g -optc-fno-dwarf2-cfi-asm -optc-Wno-pointer-sign -optc-fwrapv -optc-fno-strict-aliasing -I/usr/src/kernels/2.6.29.6-213.fc11.i586/include/ -optc-mpreferred-stack-boundary=2 -optc-march=i586 -optc-Wa,-mtune=generic32 -optc-ffreestanding -optc-mtune=generic -optc-fno-asynchronous-unwind-tables -optc-pg -optc-fno-omit-frame-pointer -fvia-c
Fun with Distributed Hash Tables
May 13, 2009
The keen reader might have previously noticed my interest in distributed hash tables (DHTs). This interest is strong enough to motivate me to build a DHT library in Haskell, which I discuss here at an absurdly high level.
Distributed Hash Table Crash Course
(skip if you’ve read anything remotely good on DHTs)
A DHT is a sort of peer to peer network typically characterized with no central or “master” node, random node addresses, and uses a form of content addressable storage. Usually implemented as an overlay network and depicted as a ring, we say each node participating in the DHT “has an address on the ring”.
To locate data first you need an address; addresses are generated in different ways for any given DHT but is commonly a hash of either the description (“Fedora ISO”), file location/name (“dht://news”), or even a hash of the file contents themselves. The lookup message is then sent to this address and in doing so will get routed to the node with the closest matching address. The routing is fish-eye: nodes have more knowledge about the nodes with closer addresses and sparse knowledge of further addresses. The result is that the average number of hops to locate a node is logarthmic to the size of the network but so are the size of any one nodes routing table, so the burden isn’t too much.
To ensure correct operation, DHTs keep track of the closest addressed nodes (typically the closest 8 on each side). These nodes make up the ‘leaf set’ and are often used for special purposes such as redundantly storing data if the DHT is for file sharing/storage. It’s “easy” to keep this correct because the final step when joining a ring is to contact the node who’s currently closest to your desired address.
Functionallity of the Haskell DHT Library
Originally I worked toward Pastry like functionallity, but then I read a paper on churn and opted to implement Chord like policies on join, stabilize and key space management.
I’ve implemented the basic operations of routing, periodic leaf set matainence, join operations requiring an atomic operation on only a single (successor) node, and IPv4 support via network-data. This is built on Control-Engine, so you can instruct nodes to route or deliver using as many haskell threads as you want. Beyond that, adding hooks is what Control-Engine is built for, so its easily to plug in modules for load conditioning, authentication, statistics gathering, and arbitrary message mutation.
Using the DHT Library
The main job in starting a node is building the ‘Application’ definition. The application must provide actions to act on delivered messages and notifications about leaf set changes and forwarded messages (giving it the opportunity to alter forwarded messages). Additionally, the app is provided with a ‘route’ method to send messages of its own. I won’t go in to depth on this right now as I’m not yet releasing the library.
Tests/Benchmarks
Using the hook instructions (and a custom Application definition) I’ve instrumented the code to log when it deals with join requests (sending, forwarding, finishing) and to show the leafset when it changes. Using the resulting logs I produced graphical representations of the ring state for various simulations (graphical work was part of a Portland State course on Functional Languages).
My student site has several simulations, but the most instructive one is LeafSet50 (22MB OGG warning!). Joining nodes are shown in the top area, active nodes are displayed in the ring at the center, thick lines are join requests being forwarded around, and groups of thin lines show the latest leaf set. Aside from revealing corrupt states caused by a broken stabilize routine, you can see some interesting facts for such a crude rendering:
A) Some areas are completely void while others are so dense that four or five nodes are overlapping almost perfectly. This tells us that, at least for sparsly populated DHTs, random assignment is horrible and can result in nodes having many orders of mangnitude larger area of responsibility than their counterparts. If I had bothered to read papers about applications based on DHT libraries then I might have known exactly how bad the situation could be, but it’s interesting to see this visually as well.
B) The simulated storm of joining nodes combined with periodic stabilization results in leaf sets being massively out of date. This concerns me less given the less-than realisic cause and the fact that everything eventually settles down (in ~120 seconds), but might bite me when I start thinking about join performance.
Other Ponderings
While I know that simulating 500 nodes takes 40% of my CPU time in the steady state (there is lots of sharing of leaf sets to make sure nothing has changed), this can be dramatically decreased by making the LeafSet data structure more efficient. Other than that, I’m just now considering the types of tests I desire to run. There are no serious benchmarks yet, but I hope to understand much more about the network performance such as:
1) Number of messages for joins
2) Number of bytes used for joins
3) Bandwidth needed for the steady state
4) Message rate in the steady state
Future Alterations:
Its not named! So job one is for me to figure out a name.
Code changes needed:
Remove nodes that don’t respond to stabilize messages (they aren’t deleted currently – they just persist).
Check the liveness of nodes appearing in the route table (only leaf set nodes are checked right now)
Generalize about the network – don’t mandate IPv4!
Polymorphic ‘Message a’ type – don’t assume H-DHT does the serialization to/from lazy bytestrings!
Stabilize is rudementary – check the sequence number to make sure responses are current!
Basic security/correctness mechanisms are still needed. When other nodes send route table rows and leaf sets we just add those entries into our own structure without any confirmation.
Protocol changes:
Implement Pastry proximity work – this will require the application to provide a function “proximity :: (NodeId, IPv4,Port) -> IO Int”.
Don’t always route to the optimal node, implement some jitter. Perhaps use the provably competative adaptive routing proposed by Awerbuch et al. for MANETs.
NAT Traversal?
Yet another proposal for Haskell – the ever growing language
March 22, 2009
What Do You Want? There’s a Haskell extension for that
We have a pure, lazy, statically typed programming language. What should we do with it? Systems Haskell? Sure! Lets also add open type functions, for correctness and extra cool points! And while we are playing with correctness, how about invariants! If this hasn’t added plenty of new keywords/syntax then we’ll throw on class aliases.
How About A Proposal Without More Syntax?
All of the above are powerful and useful – but they make the language harder to learn as well. This proposal does not add any power to the language but removes a basic restriction (unless you’re writing the compiler).
Perhaps the most common complaint from new Haskell programmers is the inabillity to overlap data field names:
data Person = Per { name :: String, age :: Int }
data Pet = Pet {name :: String, age :: Float } | Rock
The proposal is simply to allow this – but how?
Right now, fields of different types with the same name must be in different modules so the fully qualified functions are, well, different (and well typed). Instead, lets treat fields as sugar for a hidden type class. I say ‘hidden’ because the programmer would not have access to it; the class exists only in an intermediate representation. Typically the field selector is a monomorphic funciton “name :: Person -> String” and can not addiitonally be “name :: Pet -> String” but it is proposed that the type be “name :: (NameField n a) => n -> a“.
The above example would have an intermediate representation of:
data Person = Per String Int
data Pet = Pet String Float | Rock
class NameField n a where
name :: n -> a
class AgeField n a where
age :: n -> a
instance NameField Person String where
name (Per n _) = n
instance AgeField Person Int where
age (Per _ a) = a
instance NameField Pet String where
name (Pet n _) = n
name Rock = error "No field 'name' for constructor 'Rock' of type 'Pet'"
instance AgeField Pet Float where
age (Ped _ a) = a
age Rock = error "No field 'age' for constructor 'Rock' of type 'Pet'"
In other words, fields would be a concise way to define a type class and instances for the given data type.
Remaining Monomorphic
Remaining monomorphic with respect to these classes is desireable in this case 1) to avoid extra dictionaries 2) because the programmer has no access to the hidden typeclasses and cannot specify complex types such as sumAges :: (Num a, AgeField n a) => [n] -> a. So how do we reasonably respond when someone writes a function hoping to get the hidden-typeclass polymophism inferred? While non-ideal, I propose this be rejected with an Ambiguous Type message. Its worth noting that to make a sumAges function requires an explicit type class and instances – which is no more than what is currently required.
Debugging
On IRC someone mentioned this would make the debugging messages ugly. We shouldn’t complain to the developer about type classes that don’t appear in the source code.
func :: Int -> Int func i = age i ... No instance for (AgeField Int Int) arising from a use of `age' at [...] Possible fix: add an instance declaration for (AgeField Int Int)
But this isn’t that bad. What we currently get when abusing fields is:
Couldn't match expected type `Person' against inferred type `[...]'
By keeping an extra bit of information, marking each field selector function, we could probably produce an even better error message:
Inferred type `[...]' does not have field selector `age' In the first argument [...] In the expression [...] In the definition [...]
Explicit Parallelism via Thread Pools
March 13, 2009
I’m happy to say that this post is being finished up from my new home in Portland, Oregon! After many years of searching around I’ve finally decided to study at Portland State. Its probably optimisitic of me to think I’ll have more time as a graduate student, but I hope this is the beginning of much more involvement for me in the Haskell community.
Thread Pools from the Control-Engine Package
Control.Engine was recently released on hackage, providing a simple way to instantiate worker threads to split-up the processing of streaming data. Its was originally developed as a spin-off library from my DHT and I’ve since generalized it to cover numerous cases.
Trivial Thread Pools
The trivial module Control.ThreadPool can cover static examples such as a recent question asked on the haskell-cafe:
I have a function that does some IO (takes a file path, read the file, parse, and return some data), and I would like to parallelize it, so that multiple files can be parsed in parallel.
‘Control.ThreadPool’ gives us an easy answer (but not as slick as the map reduce answer the person was asking for on cafe). First we have our typical fluff.
import Control.ThreadPool (threadPoolIO)
import System.IO (openFile, IOMode(..))
import System.Environment (getArgs)
import Control.Concurrent.Chan
import Control.Monad (forM_)
import qualified Data.ByteString.Lazy.Char8 as L
main = do
as <- getArgs
As you can see below, we simply say how many threads we want in our thread pool and what action (or pure computation, using ‘threadPool’) we wish to perform. After that its just channels – send input in and read results out!
(input,output) <- threadPoolIO nrCPU op mapM_ (writeChan input) as -- input stream forM_ [1..length as] (\_ -> readChan output >>= print) where nrCPU = 4 op f = do h <- openFile f ReadMode c <- L.hGetContents h let !x = length . L.words $ c hClose h return (f,x)
And while this does nothing to demonstrate paralellism, it does work:
[tom@Mavlo Test]$ ghc -O2 parLines.hs --make -threaded -fforce-recomp
[1 of 1] Compiling Main ( web.hs, web.o )
Linking web ...
[tom@Mavlo Test]$ find ~/dev/Pastry -name *lhs | xargs ./parLines +RTS -N4 -RTS
("/home/tom/dev/Pastry/Network/Pastry/Module/Joiner.lhs",107)
("/home/tom/dev/Pastry/Network/Pastry/Config.lhs",14)
("/home/tom/dev/Pastry/Network/Pastry/Data/LeafSet.lhs",120)
("/home/tom/dev/Pastry/Network/Pastry/Data/Router.lhs",87)
("/home/tom/dev/Pastry/Network/Pastry/Data/RouteTable.lhs",75)
("/home/tom/dev/Pastry/Network/Pastry/Data/Address.lhs",152)
Control Engine Setup
The thread pools are simple, but what if you need more flexibility or power? What happens if you want to have an up-to-date state shared amoung the threads, or there’s a non-paralizable cheap computation you need to perform before the main operation? The answer is to use Control.Engine instead of Control.ThreadPool. The engine provides managed state, numerous hook location, and an abilty to inject information to mid-engine locations.
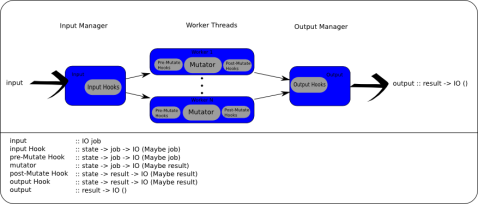
Injectors
The inject* calls can bypass the input hooks (injectPreMutator) or bypass everything besides the output hooks (injectPostMutator) – thus creating a ‘result’ that had no corrosponding ‘job’.
Hooks
Hooks are capable of modifying or filtering jobs or results. All hooks are of type state -> a -> IO (Maybe a); its important to note the type can not change and if a hook returns Nothing then the job or result stops there.
Hooks can either be input, pre-mutate, post-mutate, or output. Input and output hooks are ran in series on all jobs or results respectivly; this is intended for low computation tasks that shouldn’t be done in parallel later. Pre and post mutate hooks happen on the (parallel) worker threads before an after the main task, called the mutator.
Mutator
The engine consists of N mutator threads, which is the only operation capable of transforming the jobs into a different (result) type.
State Management
Control.Engine was built with the idea that jobs and state reads were frequent while alterations to the state were rare. A design decision was made to use STM to resolve all contention on state alterations and have a manager watch the TVar for change then bundle those changes in a quicker to read fashion (MVar) for the input, output, and worker threads.
The state provided to the hooks and mutator is always consistent but not guarenteed up-to-date. When modifications to the state occur a transactional variable is modified, which wakes the stateManager; in turn, the state manager updates the state MVar which is read by each thread before processing the next job. In the future IORefs might be used instead of the MVar – all contention is handled by the STM and the only writer for the MVar (future IORef) should be the State Manager.
Web Crawling
Now lets figure out how to help users who need more flexibility using Control.Engine instead of Control.ThreadPool.
MyCatVerbs, from #haskell, suggested a web crawler that uses URls as the job and the mutator (worker) can add all the links of the current page as new jobs while ignoring any URL that was already visited. Lets start!
The imports aren’t too surprising – tagsoup, concurrent, bloomfilter and Control-Engine are the packages I draw on.
module Main where import Control.Concurrent (forkIO, threadDelay) import Control.Concurrent.Chan import Control.Monad (forever, when) import Control.Engine -- Control-Engine import Control.Exception as X import Data.BloomFilter -- bloomfilter import Data.BloomFilter.Hash -- bloomfilter import Data.BloomFilter.Easy -- bloomfilter import Data.IORef import System.Environment (getArgs) import Text.HTML.Download -- tagsoup import Text.HTML.TagSoup -- tagsoup type URL = String data Job = GetURL URL | ParseHTML URL String deriving (Eq, Ord, Show) main = do (nrCPU:url:_) <- getArgs
The library tries to remain flexible which makes you do a little more work but don’t let that scare you! It needs an IO action to get tasks and an IO action that delivers the results. Most people will probably just want a channel, but sockets or files would do just as well.
input <- newChan output <- newChan
Starting the engine is a one line affair. You provide the number of threads, input, output, a mutator function and initial state. In return you are provided with an ‘Engine’ with which you can modify the hooks and use the injection points.
For this web crawler my ‘state’ is just a bloom filter of all visited URLs so I’ll keep that in the one hook its needed and declare the engine-wide state as a null – (). For the chosen task the mutator needs a way to add more jobs (more URLs) so as pages are parsed any new URLs can be queued for future crawling; this is handled via partial application of mutator funciton.
eng <- initEngine (read nrCPU) (readChan input) (writeChan output) (mutator (writeChan input)) ()
As mentioned, I’ll use a bloom filter to keep the web crawler from re-visiting the same site many times. This should happen exactly once for each URL and is fairly fast so I’ll insert it as an ‘Input Hook’ which means a single thread will process all jobs before they get parsed out to the parallel thread pool.
let initialBF = fromListB (cheapHashes nrHashes) nrBits []
(nrBits, nrHashes) = suggestSizing 100000 (10 ** (-6))
bf <- newIORef (initialBF,0)
let bfHook = Hk (uniqueURL bf) 1 "Ensure URLs have not already been crawled"
addInputHook eng bfHook
Finishing up main, we print all results then provide an initial URL. Notice we run forever – there’s no clean shutdown in this toy example.
forkIO $ forever $ printResult output writeChan input (GetURL url) neverStop eng where neverStop eng = forever $ threadDelay maxBound
And from here on we’re just providing the worker routine that will run across all the threads and we’ll define the input hook. TagSoup performs all the hard work of downloading the page and parsing HTML. Just pull out the <a href=”…”> tags to add the new URLs as jobs before returning any results. In this example I decided to avoid any sort of error checking (ex: making sure this is an HTML document) and simply returning the number of words as a result.
mutator :: (Job -> IO ()) -> st -> Job -> IO (Maybe (URL,Int)) mutator addJob _ (GetURL url) = forkIO (do e <- X.try (openURL url) :: IO (Either X.SomeException String) case e of Right dat -> addJob (ParseHTML url dat) _ -> return () ) >> return Nothing mutator addJob _ (ParseHTML url dat) = do let !urls = getURLs dat !len = length urls fixed = map (\u -> if take 4 u /= "http" then url ++ '/' : u else u) urls mapM_ (addJob . GetURL) fixed return $ Just (url,len) where getURLs :: String -> [URL] getURLs s = let tags = parseTags s in map snd (concatMap hrefs tags) hrefs :: Tag -> [(String,String)] hrefs (TagOpen "a" xs) = filter ( (== "href") . fst) xs hrefs _ = [] printResult :: (Show result) => Chan result -> IO () printResult c = readChan c >>= print
Filtering out non-unique URLs is just the bloom filter in action.
uniqueURL :: IORef (Bloom URL, Int) -> st -> Job -> IO (Maybe Job)
uniqueURL _ _ j@(ParseHTML _ _) = return $ Just j
uniqueURL bf _ j@(GetURL url) = do
(b,i) <- readIORef bf
if elemB url b
then putStrLn ("Reject: " ++ url) >> return Nothing
else do writeIORef bf (insertB url b, i + 1)
when (i `rem` 100 == 0) (print i)
return $ Just j
Performance
P.S. No serious performance measurements have been made beyond extremely expensive (and trivially parallel) problems, so those don’t count.
14Mar2009 EDIT: Said something about Control.Engine before showing the diagram to make reading smoother.
EDIT2: ThreadPool example shown was a version using MD5, not length – oops! Fixed now.
hsXenCtrl and pureMD5
August 7, 2008
On vacation I found some time to upload the new hsXenCtrl library (0.0.7) and pureMD5 (0.2.4)
The new hsXenCtrl includes the System.Xen module, which is a WriterT ErrorT transformer stack and a brief attempt at ‘Haskellifying’ the xen control library. I find it much more useful for simple tasks like pausing, unpasing, creating and destroying domains. The API is still subject to change without notice as plenty of function are still very ‘C’ like (ex: scheduler / sedf functions).
pureMD5 received a much smaller change – some users noticed the -fvia-c caused compilation headaches on OS X. After removing the offending flag, some benchmarks revealed no measureable difference in speed, so this is an over-due change. OS X users rejoice!
Past and Future libraries
June 18, 2008
Hello planet, as my first post that gets placed on planet.haskell.org I decided to do a quick recap of the libraries I maintain and muse about future libraries. My past posts include why static buffers make baby Haskell Curry cry and fun academic papers.
The Past
* pureMD5: An implementation of MD5 in Haskell using lazy ByteStrings. It performs within an order of magnitude of the typical ‘md5sum’ binary, but has known inefficiencies and could be improved.
* ipc: A trivial to use inter-process communication library. This could use some work, seeing as structures that serialize to over 4k get truncated currently. I’ll probably only come back to this if I end up with a need for it.
* control-event: An event system for scheduling and canceling events, optimized for use with absolute clock times.
The Present
* hsXenCtrl: This library is intended to open the doors for Haskell apps to interact with and perhaps manage Xen. Currently its just straight forward ‘c’ bindings to an old version of <xenctrl.h>, but the intent is to build a higher level library with useful plumbing.
* NumLazyByteString: Not sure if I’ll bother finishing this one, but it adds ByteString to the Num, Enum, and Bits type classes. I just thought it would be funny to have lazy adding allowing: L.readFile “/dev/urandom” >>= \a -> print (a + a `mod` 256)
The Future
I tend to be a bit of a bouncing ball in terms of what nterests me. Near and mid-term tasks will probably be a couple of these:
* A .cabal parser that can create a dependency graph for Haskell packages (not modules). But should I use an outside package like graphviz or go pure / self contained Haskell?
* An implementation of something distributed like a P2P or ad-hoc networking protocol. Would this be Pastry then Awerbuchs work or OLSR2? These would be large tasks with their own ups and downs.
* Finally learn happs and make some sort of web Xen management system using hsXenCtrl.
* Learn Erlang – just because it looks cool too.
* Forget programming (and blogging) – read more TaPL!
